Jaco Deep Grasps
Description
This project is my capstone for the Master of Science in Robotics (MSR) program at Northwestern University. In this project, I built on MoveIt Deep Grasps and implemented autonomous grasping on a 7-DOF Kinova Jaco 2 arm (j2s7s300). The aim of this project is to facilitate activities of daily living (ADLs) and assist people who may not be able to perform daily tasks.
This project was in collaboration with argallab at Northwestern, which focuses on rehabilitative and assistive robotics.
Originally designed in simulation only and on a Franka Panda robot, some of my modifications and additions from MoveIt Deep Grasps include:
- Adaptation to the Kinova Jaco arm
- Translation to live hardware trajectory execution
- Live point cloud generation, segmentation, and filtering
- YOLOv8 object detection to provide semantic labeling and segmentation parameters for the object to grasp
This project largely uses ROS Noetic in C++ and Python.
Live Demo
This is a live video of the demo along with the corresponding computer screencast showing YOLO object detection and visualization in Rviz.
Software and Hardware
Repositories
jaco_deep_grasp is the main repository for this project. Instructions on cloning and using the other related repositories can be found in the README for jaco_deep_grasp.
Additionally, the entire demo can be set up inside a Docker container, the Dockerfile and instructions for which are also in jaco_deep_grasp.
Note: jaco_base is an argallab repository and not currently publicly available. It includes modifications to kinova-ros that allow this project to work.
Hardware Requirements
- Intel RealSense Depth Camera D435i (both simulation and hardware)
- Use a USB 3.2 or better cable for best results
- 7-DOF Kinova Jaco Gen2 arm - j2s7s300 (only required for hardware demo)
Workflow
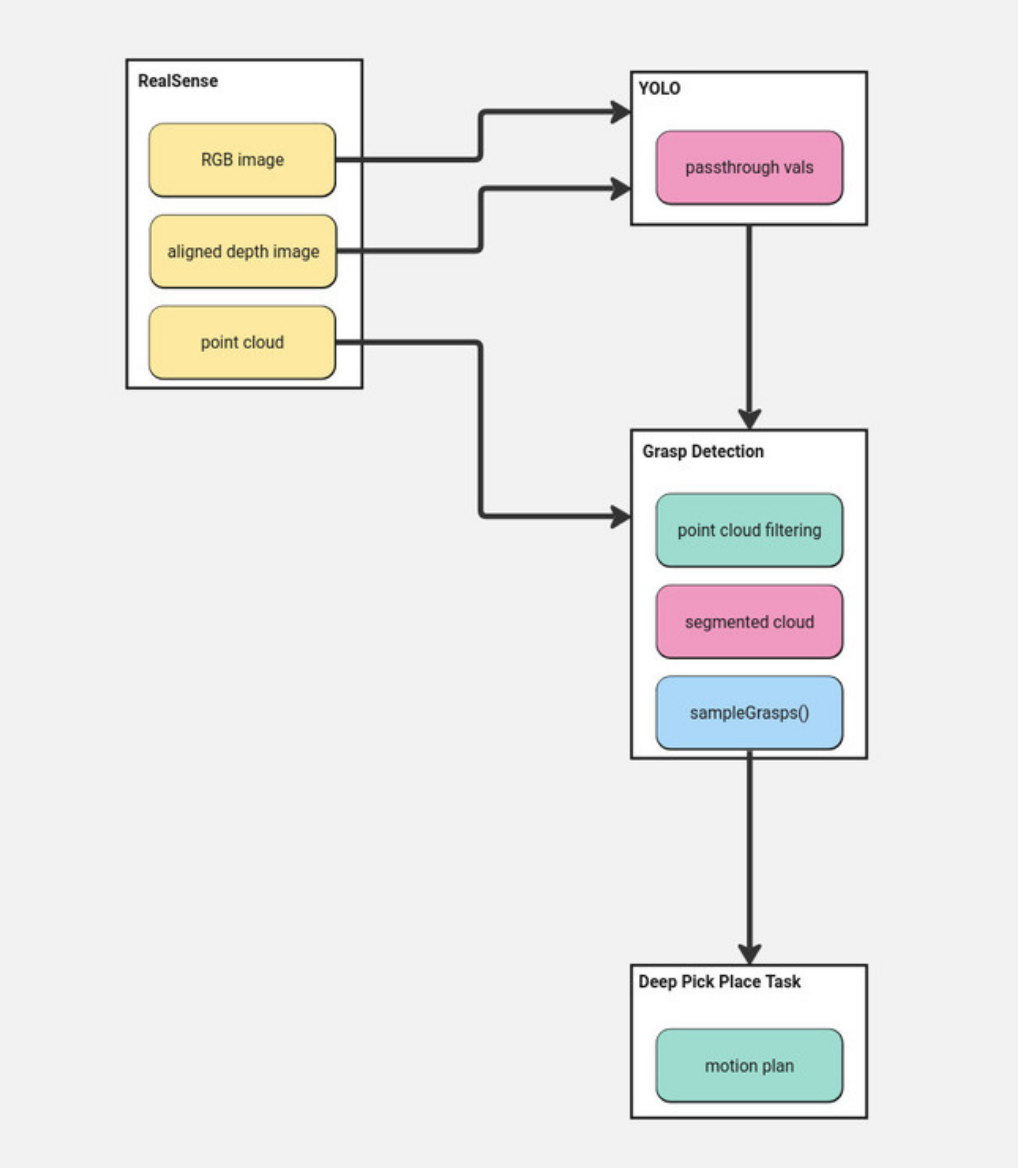
The object_detection node uses YOLOv8 with the built-in, pre-trained model to detect common objects such as bottles, cups, bowls, and others. A bounding box is generated around the detected objects, and if an object matches the user’s desired object, information is sent to the grasp_detection node.
In the grasp_detection node, point cloud data is received and segmented based on the bounding box coordinates from YOLO. Other filters are applied to remove outliers and refine the segmented point cloud that is then passed into the Grasp Pose Detection (GPD) neural network for generating grasp poses.
After grasp candidates are generated, if any are viable the deep_grasp_task node generates a plan to move to pick and place the object. If the plan is succesful, the trajectory is executed. If the plan is unsuccessful, it will retry up to 5 times before asking the user to restart.
Computer Vision and Object Detection
With the RealSense camera, I collected RGB images, point cloud data, and depth images.
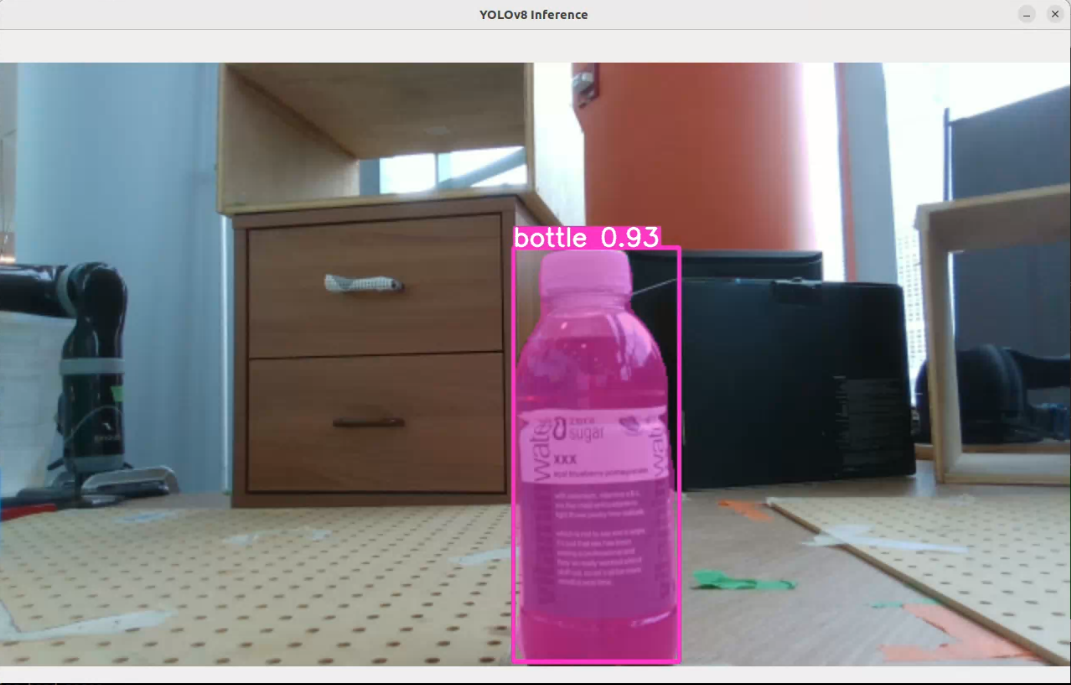
The RGB image feed is used with YOLOv8 object detection, which provides semantic labeling for the objects it sees as well as creating corresponding bounding boxes. From these, the object of interest can be isolated by name and its coordinates extracted from the bounding box. Using a deprojection function along with the corresponding depth image, coordinates in the RGB image are converted into 3D points in cartesian space, matching our data format for the point clouds. Here is an example of detecting a bottle:
The point clouds allowed for capturing the geometry of the object to grasp, and a filtered version is passed into GPD for generating grasps. To filter the point cloud, I use a passthrough filter followed by radius outlier removal and a voxel grid filter. Below are the results of the point cloud filtering:


Unfinished Work and Next Steps
The generate-collision-object branch in the deep_grasp_demo and jaco_deep_grasp repositories contain unfinished work towards dynamically generating a collision object based on information from YOLO. This would enable the user to place the object anywhere in the workspace and have MoveIt plan to an object location without having to predefine it in the kinova_object.yaml file that gets loaded into the ROS parameter server. Functionality for placing the object anywhere is already in place for point cloud segmentation and YOLO object detection.
The main issue I was running into was integrating this newly-generated object to be sent as a goal to MoveIt using the existing architecture of deep grasps.
Additionally, work remains to be done for dynamic grip widths for different objects. Unlike the Franka Panda arm, the Kinova Jaco arm I used did not have force sensors in the fingers, meaning open and close poses for the gripper were based purely on joint positions. For objects of different sizes, this proved challenging because the close pose would have to be tight enough to grasp the object, but not so tight that the controller could never reach the specified joint positions because of the object’s size (this would cause the trajectory execution to abort).
Acknowledgements
I’d like to give a huge thanks to my MSR advisors Dr. Matt Elwin and Dr. Todd Murphey, as well as Dr. Brenna Argall for welcoming me into her lab. Also, an immense gratitute to Andrew Thompson, a doctoral candidate in argallab who was extremely helpful in guiding and assisting me throughout this project.